 Your team has one of those long roadmaps or a long backlog. They're working, delivering about two items (full stories) a week.
Your team has one of those long roadmaps or a long backlog. They're working, delivering about two items (full stories) a week.
Then, your manager asks you this question: “That feature set in six months: when will you start it and when will you finish it?”
“We could start it now,” you say, “assuming we can stop these feature sets.”
“No,” the manager says. “Finish what you're doing now. But when will you start and finish that specific feature set?”
“Let me get this straight,” you say. “We're in Q1 and you want me to tell you when the team will start Feature Set A in Q4 and when they'll finish?”
“Yes.”
What do you say?
Here are some options:
- Estimate all the features in the feature set, breaking them down into tasks, using story points or clock time, your choice. (It doesn't matter.) Offer a three-date estimate because you know Things Happen.
- Run a Monte Carlo simulation, using your current cycle time. Show the manager your best guess, and explain the various dates by using the explanation of how forecasters deal with hurricanes.
- Count the stories you finished last quarter. Count the stories in that feature set. Use your best judgment as to how many more stories there might be. And offer a three-date estimate.
- Explain that you have no idea and no one else has any idea either.
Here's how all of these work.
Estimate Using Some Form of Breakdown
 When we break down stories into tasks, we all (because we're human) add a little buffer to deal with the uncertainty. The larger the task, the more buffer we add.
When we break down stories into tasks, we all (because we're human) add a little buffer to deal with the uncertainty. The larger the task, the more buffer we add.
If the team implements through the architecture, they tend to avoid all those little buffers (see the first image in this section). But if the team implements across the architecture, or because of component teams, they have curlicue features, they will add even more buffer.
 Component teams add more time because they integrate later. (See How Long Are Your Iterations, Part 2) for these two images and the entire explanation.
Component teams add more time because they integrate later. (See How Long Are Your Iterations, Part 2) for these two images and the entire explanation.
But top-down requirements breakdown always creates more buffer in the estimate. That leads to things taking longer. (See Little’s Law for Any Kind of Product Development: How to Learn How Long Your Work Will Take.)
So, while you can break requirements apart, the more you break them into tasks, the longer the work will take.
If you're like me, you stopped breaking requirements apart ages ago. I asked teams to tell me what they could deliver in the next 3-4 weeks.
But that's not going to satisfy your manager. You have more choices, starting with using a Monte Carlo simulation.
Run a Monte Carlo Simulation
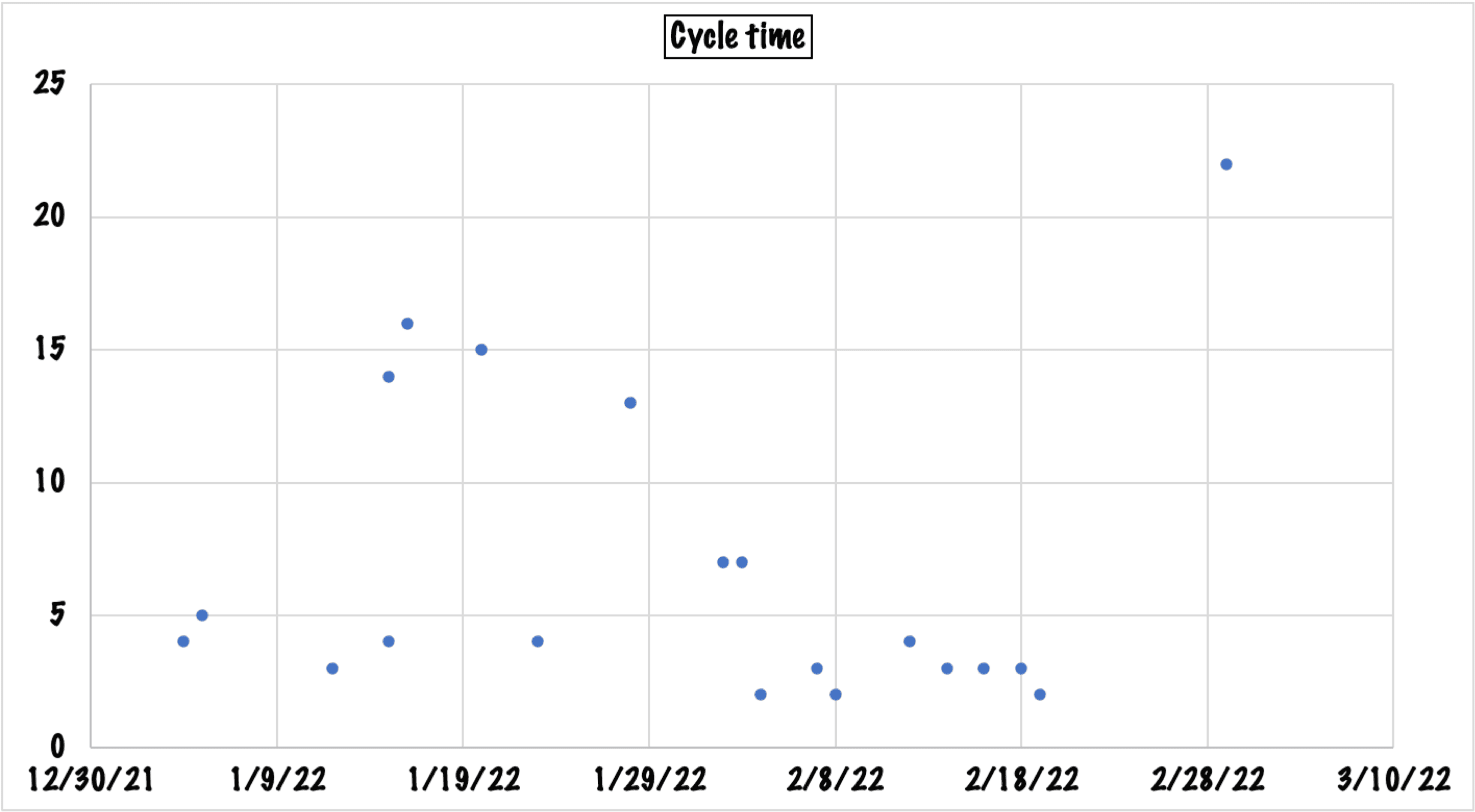 A Monte Carlo simulation aggregates many possibilities of cycle time, based on your previous cycle times. (See the image to the left.)
A Monte Carlo simulation aggregates many possibilities of cycle time, based on your previous cycle times. (See the image to the left.)
You need this data:
- How many items did your team finish in each of the previous six months? (Notice, I said “items” and not “tasks.” That's because your boss wants to know about feature sets some months in the future.
- What was the cycle time for each of those items?
- How much WIP (Work in Progress) does your team typically have? The higher the WIP (in general), the lower the throughput.
Use the various plugins for your favorite spreadsheet, plug those numbers in, and you have a range of dates. (Also, read Feature Monte Carlo for many more details than I've offered here.)
Since you get a range of dates, explain that the farther away your estimate is, the less confidence you have in any specific date. If you talk about how forecasters hone in on a hurricane's location much closer to the event, your manager will probably understand.
Since all computers have access to modern spreadsheets, Monte Carlo simulations are easy to run, as long as you have the data. However, story points mean nothing in this kind of simulation. You've got to have cycle time and the number of stories, that throughput idea again.)
You do have some data, which is roughly two stories per week. Some weeks, your team finishes more, some weeks, they finish less. But you could use that data to try to predict what you can do four quarters from now.
Since that seems nuts to me, I prefer to count stories.
Count Stories Historically and for the Future
In my experience, when product leaders and teams collaborate on creating backlogs, their feature sets tend to have a similar number of stories. One client has feature sets that range from 10-15 stories. Another client has feature sets that range from 30-40 stories. So we can't compare my clients. But these clients have (somewhat) right-sized their feature sets.
That means anyone can count the stories in a previous feature set, measure that feature set's cycle time, and repeat for all the feature sets. Plot those feature sets with the number of stories on one axis and the cycle time on another axis. This cycle time image above is for features, but it's the same idea for feature sets. (Because your manager wants to know your start and end time for the feature set.)
Now, count the stories in that future feature set. Given your past data, where would you place that feature set? You see it's in a range of possible durations, which makes sense to me.
But let me go a little meta. All these possible answers are hooey. No one has any freaking idea.
While I understand why managers want to know, that question does not have a correct or even possibly correct answer.
An Unknowable Question
Let me use an analogy with much more predictability than software development: my lunch. My lunch ranges from eggs, chicken salad, or leftovers for lunch every single day. I also eat one of three vegetables: leftover veggies from a previous dinner, guacamole, or cauliflower rice with garlic. (My boring predictable lunches are my problem, not yours.)
That's only three mains and three veggies, but I have at least 9 permutations (I hope I did this right. If I did this wrong, please tell me. I hate doing public math.)
What will I eat for lunch six months from today, on Feb 21, 2024? Hmm, I might not be home, which means I might have some other option for lunch.
I can predict I will eat lunch. I'm pretty sure I will have a low-carb lunch. But my specific lunch, my specific combination of protein and veggies? I can't answer that question.
If I can't predict what I will eat for lunch six months in advance—and my lunch decisions only involve me—how can you possibly predict what you will deliver in the future? You can't know what. All you know is that you will deliver something.
It's time to recast the question and answer it differently. But this post is already too long, so I'll do a Part 2.
Johanna,
John Voris of the old AgilePhilly – – I think you have some great blog postings here, but I get an error in Foxfire of ____ but using MS Edge, the articles appear fine. Just an FYI.
John Voris
This was AOK from your Twitter post:
https://www.jrothman.com/mpd/2023/08/how-to-steer-the-conversation-when-someone-asks-for-a-specific-backlog-item-prediction-part-2/?utm_source=dlvr.it&utm_medium=twitter
But this link at the bottom had the error in FireFox: How to Predict When the Team Will Complete a Specific Backlog Item, Part 1 …
https://www.jrothman.com/mpd/2023/08/how-to-predict-when-the-team-will-complete-a-specific-backlog-item-part-1/
Content Encoding Error
An error occurred during a connection to http://www.jrothman.com.
Please contact the website owners to inform them of this problem.
Hi John, nice to hear from you! I don’t use any PCs nor do I use Firefox. However, I did find this: https://support.mozilla.org/en-US/questions/1163431. I don’t think it’s something I can fix, even though the error message says I should. I think only you can fix this.
Thanks for reading… and let me know what happens.
John, one more thing: I just tried these links in Firefox on my Mac, and everything loads just fine. That means I can’t fix this.